
数据预处理:清洗与特征工程

数据采样在整个数据挖掘过程中扮演着至关重要的角色,它不仅能够帮助我们更好地理解和利用数据,还能有效提高模型的泛化能力。首先,需要对原始数据进行清洗,以去除异常值、缺失值以及其他可能影响分析结果的噪声。接着,我们通过特征工程来选择或构造最有价值的特征,这通常涉及到变量转换、组合以及降维等操作。
过滤采样:简单而高效
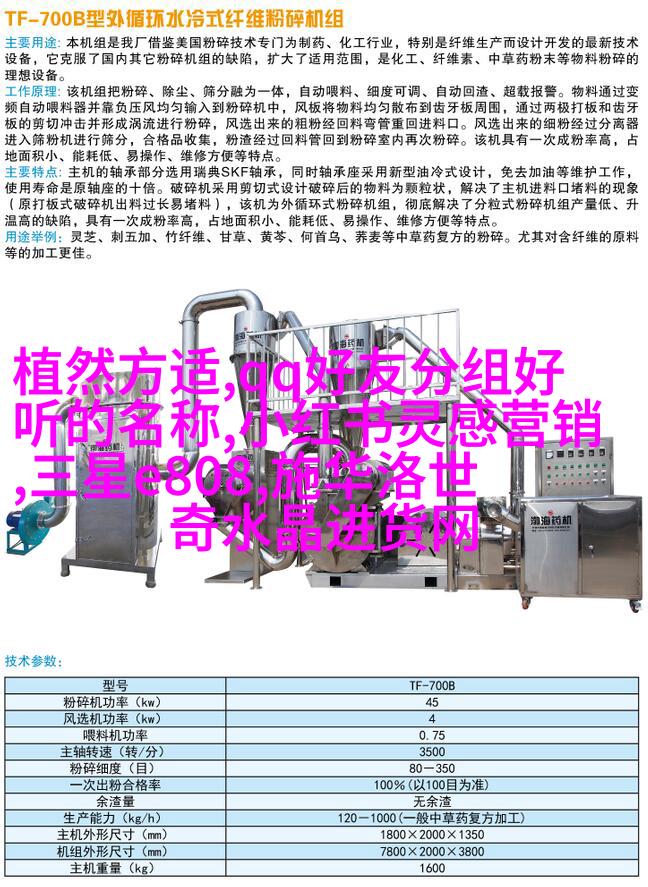
过滤采样是一种常见且直接的方法,它通过筛选出满足某一条件或范围内的记录来实现目标。这包括随机抽样的策略,比如随机抽取一定比例或者数量级别的小部分,并将其用于训练模型。在使用过滤采样的过程中,关键是确保所选出的子集能够代表原有分布,并且尽量减少偏差。
聚类分群:基于相似度
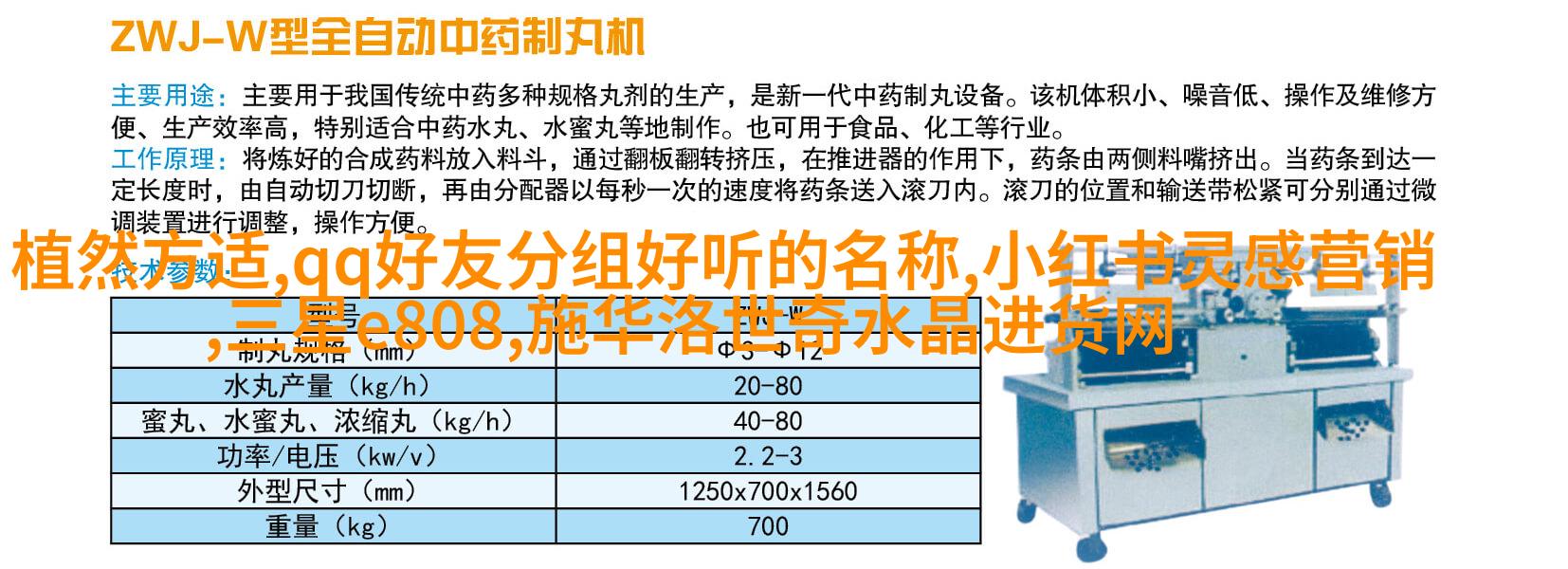
在某些情况下,我们可以采用聚类分群技术来识别具有相似性质或模式的一组对象,然后从这些聚类中随机选择个体作为我们的采样对象。这种方法特别适用于那些难以定义明确边界但又具有一定规律性的问题领域,如市场细分、用户行为分析等。
模拟多重迭代法: 优化性能
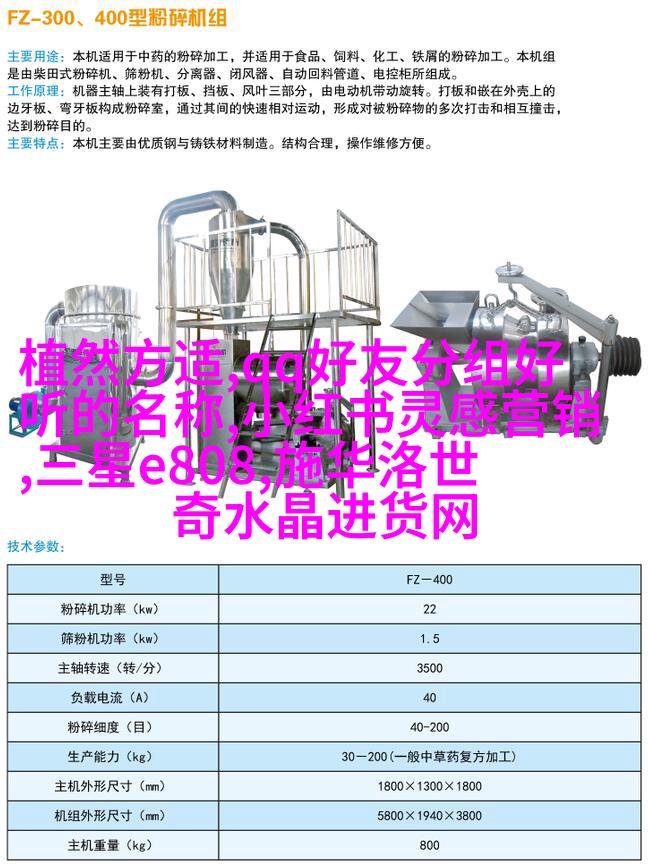
模拟多重迭代法是一种更加复杂但效果显著的手段,它允许我们根据具体情境调整参数并不断迭代优化。在这个过程中,通过交叉验证和网格搜索等方法,可以找到最佳配置,从而提升了整体模型性能。此外,这种策略还可应用于增强现有的算法,使其适应新的环境和挑战。
自适应学习: 对抗式对比学习

随着深度学习技术的大幅发展,对抗式对比学习成为了研究人员们探索新奇解决方案的一条道路。在这一框架下,一个代理被设计成不断试图欺骗另一个代理(称为攻击者),而攻击者则努力识别并抵御这些攻击。这样的双向竞争关系促使系统在不断进化,最终达到一种平衡状态,即既不会完全成功也不会完全失败,而这正是良好训练效果所需达到的状态。